When discussing the scalability of Web services there seems to be a tendency for some developers to overly focus on the framework being used, based on the mistaken assumption that smaller means faster, rather than considering the architecture of the application as a whole. We've seen several cases of developers making these assumptions before they start building their API, and either discounting Django as not being fast enough for their needs, or deciding to not use a Web API framework such as Django REST framework because they 'need something lightweight'.
I'm going to be making the case that Web API developers who need to build high performance APIs should be focusing on a few core fundamentals of the architecture, rather than concentrating on the raw performance of the Web framework or API framework they're using.
Using a mature, fully featured and well supported API framework gives you a huge number of benefits, and will allow you to concentrate your development on the things that really do matter, rather than expending energy reinventing the wheel.
Much of this article is Django/Python specific, but the general advice should be applicable to any language or framework.
Dispelling some myths
Before we get started, I'd like to first counter some bits of what I believe are misguided advice that we've seen given to developers who are writing Web APIs that need to service thousands of requests per second.
Roll your own framework.
Please: don't do this. If you do nothing else other than use Django REST framework's plain APIView and ignore the generic views, serialization, routers and other advanced functionality, you'll still be giving yourself a big advantage over using plain Django for writing your API. Your service will be a better citizen of the Web.
Use a 'lightweight' framework.
Don't conflate a framework being fully-featured with being tightly coupled, monolithic or slow. REST framework includes a huge amount of functionality out of the box, but the core view class is really very simple.
REST framework is tied to Django models.
Nope. There are a default set of generic views that you can easily use with Django models, and default serializer subclasses that work nicely with Django models, but those pieces of REST framework are entirely optional, and there's absolutely no tight coupling to Django's ORM.
Django/Python/REST framework is too slow.
As this article will argue, the biggest performance gains for Web APIs can be made not by code tweaking, but by proper caching of database lookups, well designed HTTP caching, and running behind a shared server-side cache if possible.
Profiling our views
We're going to take a broad look at profiling a simple Django REST framework API in order to see how it compares against using plain Django views, and get some idea where the biggest performance improvements gains can be had.
The profiling approach used here is absolutely not intended as a comprehensive performance metric, but rather to give a high level overview of the relative performance of various components in the API. The benchmarks were performed on my laptop, using Django's development server and a local PostgreSQL database.
For our test case we're going to be profiling a simple API list view.
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ('id', 'username', 'email')
class UserListView(APIView):
def get(self, request):
users = User.objects.all()
serializer = UserSerializer(users)
return Response(serializer.data)There are various components that we're interested in measuring.
- Database lookup. Here we're timing everything from the Django ORM down to the raw database access. In order to time this independently of the serialization we'll wrap the queryset call in a
list()in order to force it to evaluate. - Django request/response cycle. Anything that takes place before or after the view method runs. This includes the default middleware, the request routing and the other core mechanics that take place on each request. We can time this by hooking into the
request_startedandrequest_finishedsignals. - Serialization. The time it takes to serialize model instances into simple native python data structure. We can time this as everything that takes place in the serializer instantiation and
.dataaccess. - View code. Anything that runs once an
APIViewhas been called. This includes the mechanics of REST framework's authentication, permissions, throttling, content negotiation and request/response handling. - Response rendering. REST framework's
Responseobject is a type of TemplateResponse, which means that the rendering process takes place after the response has been returned by the view. In order to time this we can wrapAPIView.dispatchin a superclass that forces the response to render before returning it.
Rather than use Python's profiling module we're going to keep things simple and wrap the relevant parts of the the code inside timing blocks. It's rough and ready (and it goes without saying that you wouldn't use this approach to benchmark a "real" application), but it'll do the job.
Timing the database lookup and serialization involves modifying the .get() method on the view slightly:
def get(self, request):
global serializer_time
global db_time
db_start = time.time()
users = list(User.objects.all())
db_time = time.time() - db_start
serializer_start = time.time()
serializer = UserSerializer(users)
data = serializer.data
serializer_time = time.time() - serializer_start
return Response(data)In order to time everything else that happens inside REST framework we need to override the .dispatch() method that is called as soon as the view is entered. This allows us to time the mechanics of the APIView class, as well as the response rendering.
def dispatch(self, request, *args, **kwargs):
global dispatch_time
global render_time
dispatch_start = time.time()
ret = super(WebAPIView, self).dispatch(request, *args, **kwargs)
render_start = time.time()
ret.render()
render_time = time.time() - render_start
dispatch_time = time.time() - dispatch_start
return retFinally we measure the rest of the request/response cycle by hooking into Django's request_started and request_finished signals.
def started(sender, **kwargs):
global started
started = time.time()
def finished(sender, **kwargs):
total = time.time() - started
api_view_time = dispatch_time - (render_time + serializer_time + db_time)
request_response_time = total - dispatch_time
print ("Database lookup | %.4fs" % db_time)
print ("Serialization | %.4fs" % serializer_time)
print ("Django request/response | %.4fs" % request_response_time)
print ("API view | %.4fs" % api_view_time)
print ("Response rendering | %.4fs" % render_time)
request_started.connect(started)
request_finished.connect(finished)We're now ready to run the timing tests, so we create ten users in the database. The API calls are made using curl, like so:
curl http://127.0.0.1:8000We make the request a few times, and take an average. We also discount the very first request, which is skewed, presumably by some Django routing code that only need to run at the point of the initial request.
Here's our first set of results.
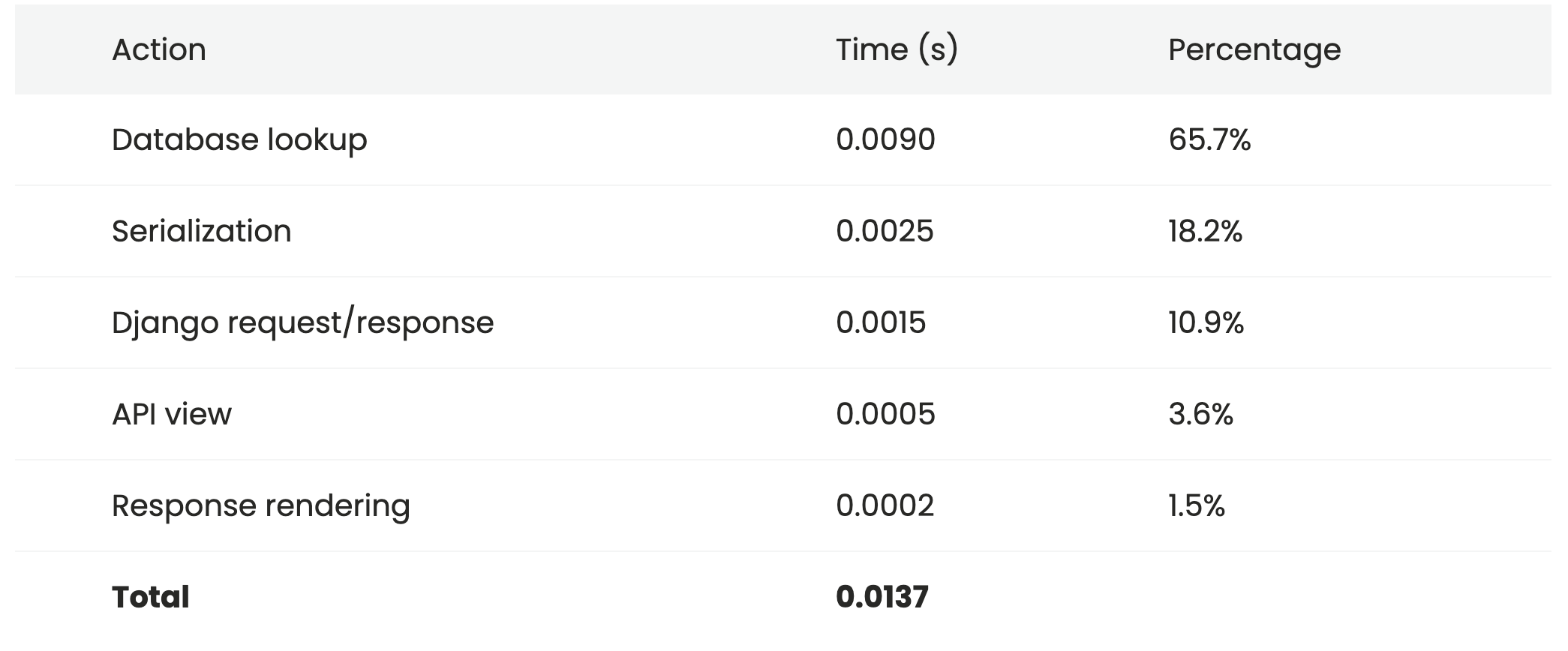
Removing serialization
Let's simplify things slightly. At the moment we're returning fully fledged model instances from the ORM, and then serializing them down into simple dictionary representations. In this case that's a little unnecessary - we can simply return simple representations from the ORM and return them directly.
class UserListView(APIView):
def get(self, request):
data = User.objects.values('id', 'username', 'email')
return Response(data)Serializers are really great for providing a standard interface for your output representations, dealing nicely with input validation, and easily handling cases such as hyperlinked representations for you, but in simple cases like this they're not always necessary.
Once we've removed serialization, our timings look like this.
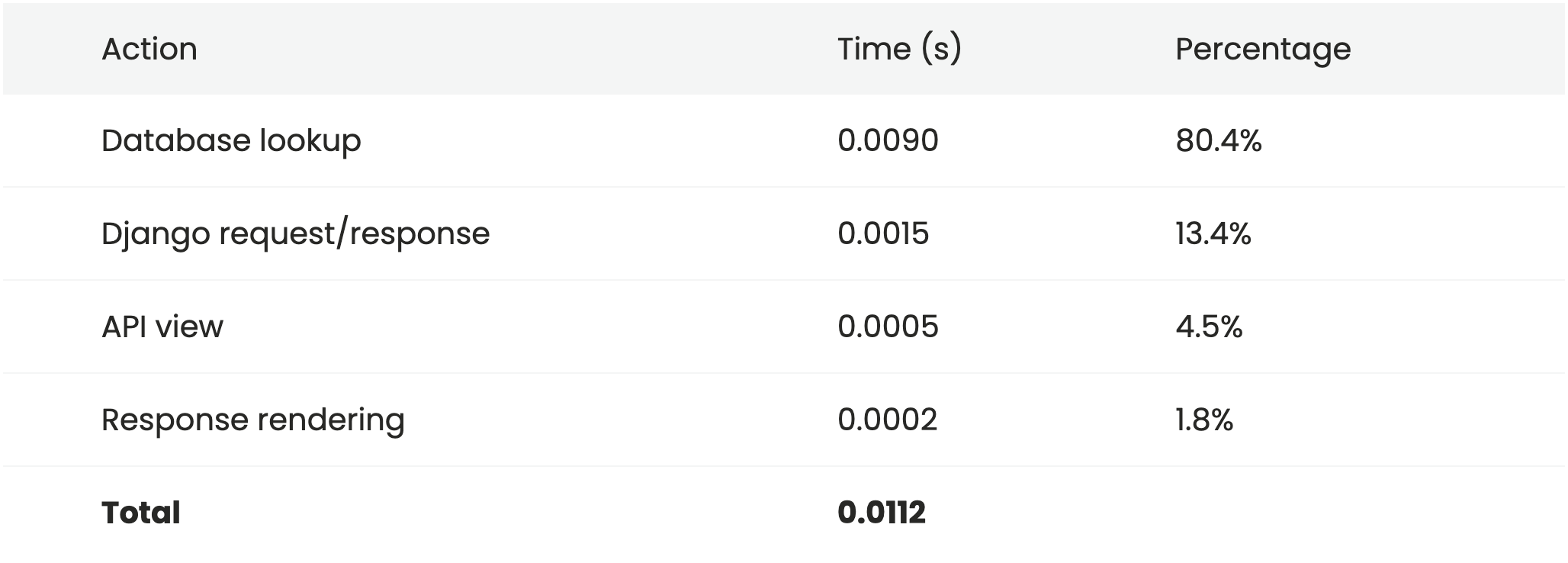
It's an improvement (we've shaved almost 20% off the average total request time), but we haven't dealt with the biggest issue, which is the database lookup.
Cache lookups
The database lookup is still by far the most time consuming part of the system. In order to make any significant performance gains we need to ensure that the majority of lookups come from a cache, rather than performing a database read on each request.
Ignoring the cache population and expiry, our view now looks like this:
class UserListView(APIView):
def get(self, request):
data = cache.get('users')
return Response(data)We set up Redis as our cache backend, populate the cache, and re-run the timings.
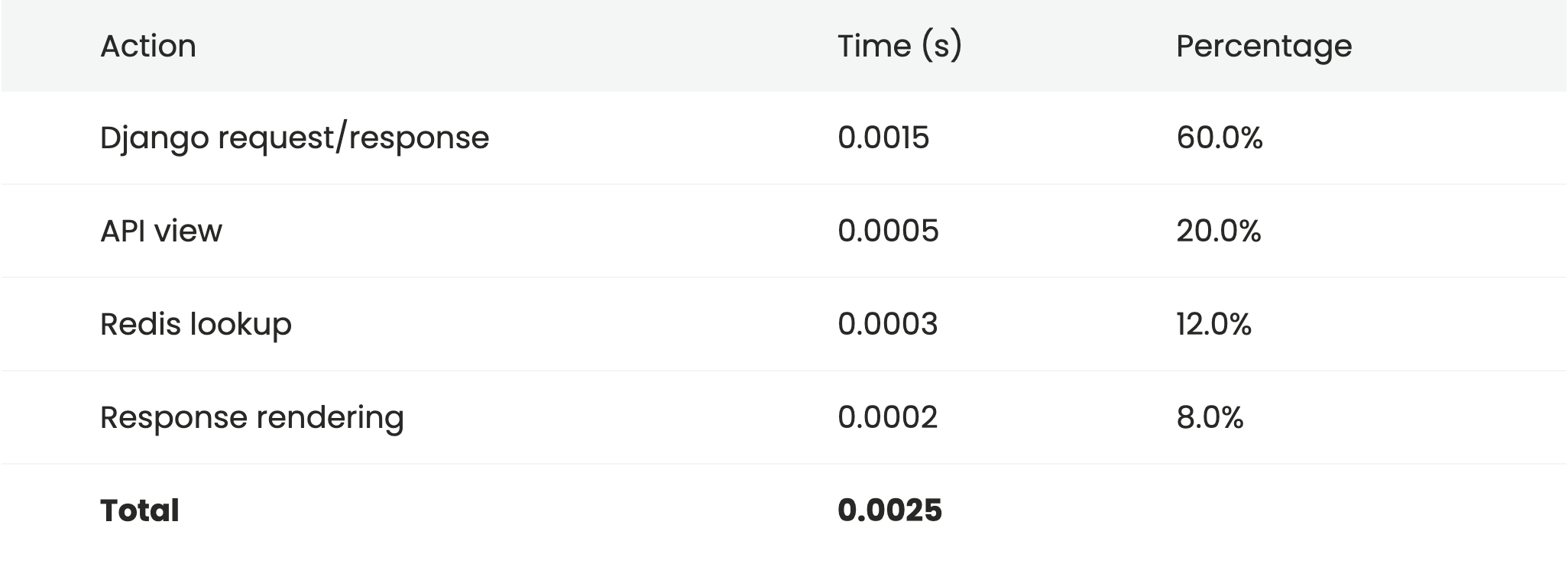
As would be expected, the performance difference is huge. The average request time is over 80% less than our original version. Lookups from caches such as Redis and Memcached are incredibly fast, and we're now at the point where the majority of the time taken by the request isn't in view code at all, but instead is in Django's request/response cycle.
Slimming the view
The default settings for REST framework views include both session and basic authentication, plus renderers for both the browsable API and regular JSON.
If we really need to squeeze out every last bit of possible performance, we could drop some of the unneeded settings. We'll modify the view to stop using proper content negotiation using the IgnoreClientContentNegotiation class demonstrated in the documentation, remove the browsable API renderer, and turn off any authentication or permissions on the view.
class UserListView(APIView):
permission_classes = []
authentication_classes = []
renderer_classes = [JSONRenderer]
content_negotiation_class = IgnoreClientContentNegotiation
def get(self, request):
data = cache.get('users')
return Response(data)Note that we're losing some functionality at this point - we don't have the browsable API anymore, and we're assuming this view can be accessed publicly without any authentication or permissions.
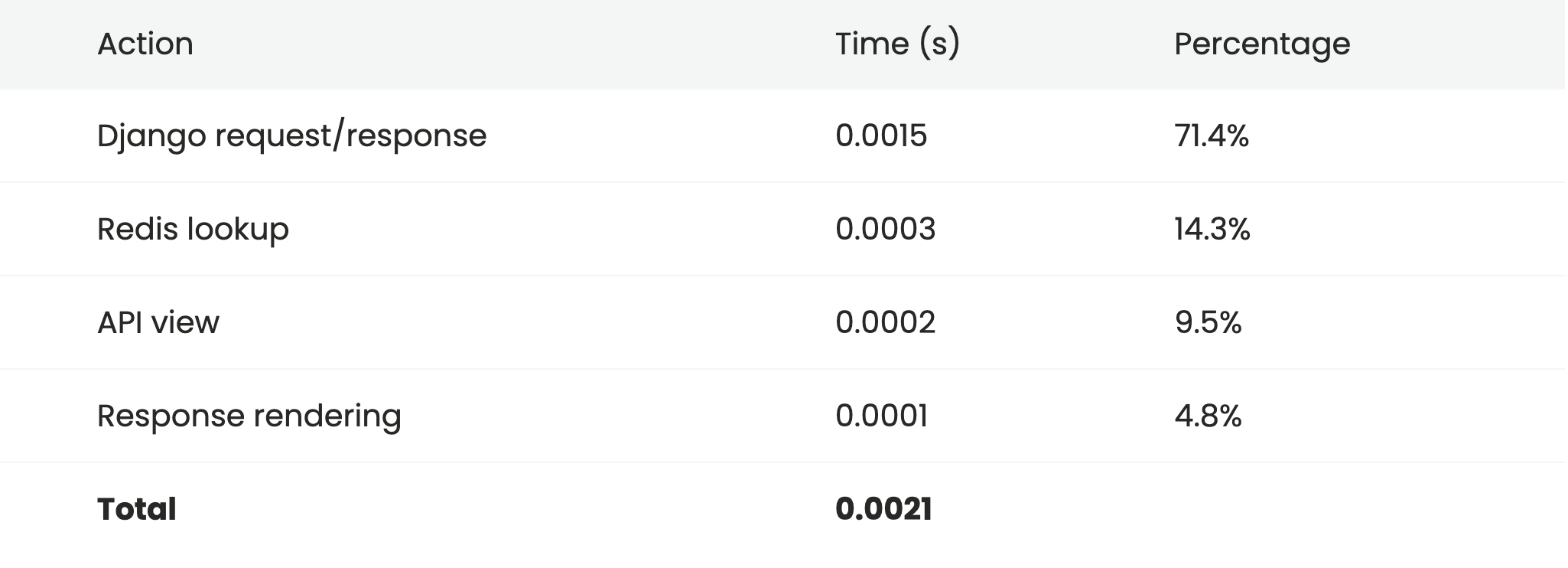
That makes some tiny savings, but they're not really all that significant.
Dropping middleware
At this point the largest potential target for performance improvements isn't anything to do with REST framework, but rather Django's standard request/response cycle. It's likely that a significant amount of this time is spent processing the default middleware. Let's take the extreme approad and drop all middleware from the settings and see how the view performs.
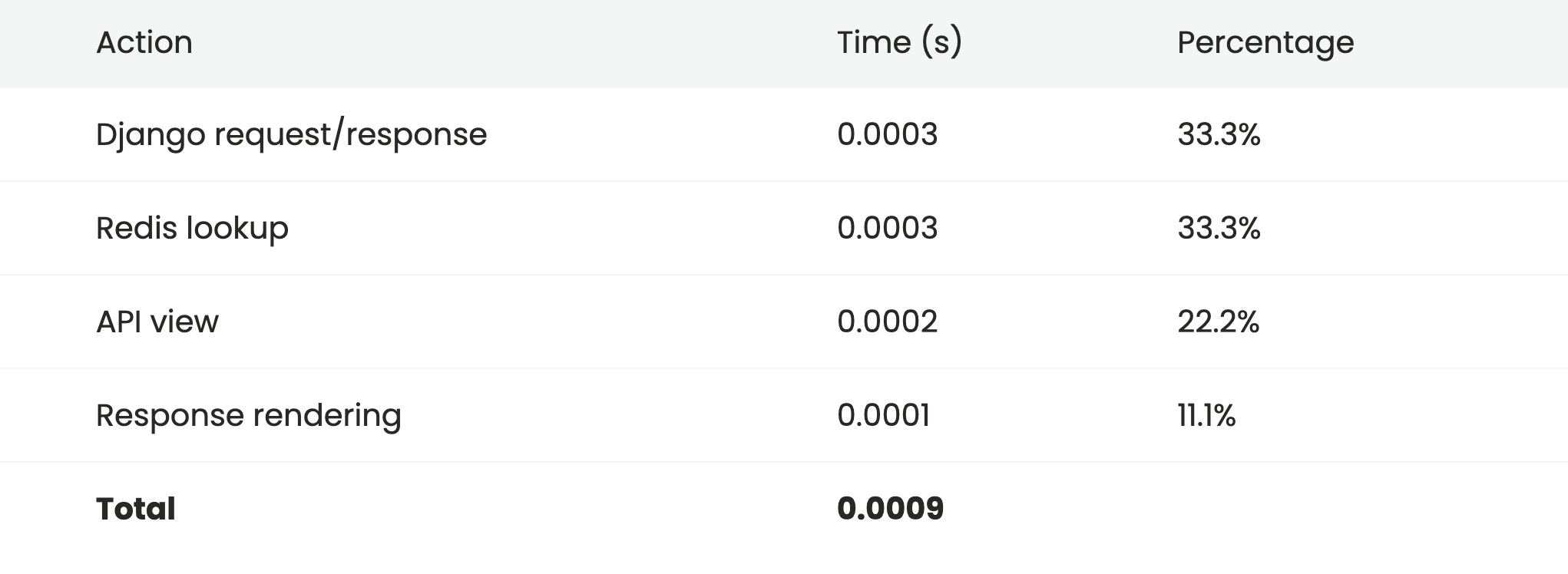
In almost all cases it's unlikely that we'd get to the point of dropping out Django's default middleware in order to make performance improvements, but the point is that once you're using a really stripped down API view, that becomes the biggest potential point of savings.
Returning regular HttpResponses
If we're still need a few more percentage points of performance, we can simply return a regular HttpResponse from our views, rather than returning a REST framework Response. That'll give us some very minor time savings as the full response rendering process won't need to run. The standard JSON renderer also uses a custom encoder that properly handles various cases such as datetime formatting, which in this case we don't need.
class UserListView(APIView):
permission_classes = []
authentication_classes = []
renderer_classes = [JSONRenderer]
content_negotiation_class = IgnoreClientContentNegotiation
def get(self, request):
data = cache.get('users')
return HttpResponse(json.dumps(data), content_type='application/json; charset=utf-8')This gives us a tiny saving over the previous case.
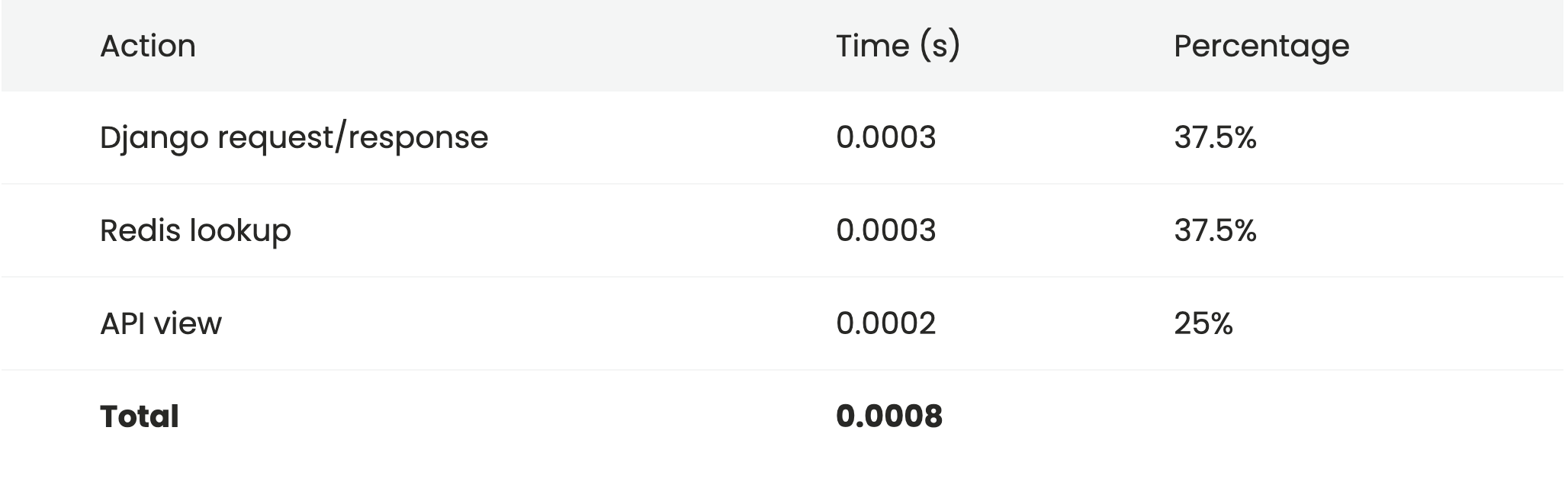
The final step would be to stop using REST framework altogether and drop down to a plain Django view. This is left as an exercise for the reader, but hopefully by now it should be clear that we're talking about tiny performance gains that are insignificant in all but the most extreme use-cases.
Comparing our results
Here's the full set of results from each of our different cases.
The areas in pink/red tones indicate bits of REST framework, the blue is Django, and the green is the database or Redis lookup.

Remember that these figures are really only intended as a rough insight into these relative timings of the various components. Views with more complex database lookups, paginated results, or write actions will all have very different characteristics. The important thing to point out is that the database lookup is the limiting factor.
In our basic un-optimized case your application will run pretty much at the same rate as any other simple Django view. We've not run ApacheBench against these setups, but you might reasonably expect to be able to achieve a rate of a few hundred requests per second on a decent setup. For the cached case you might be looking at closer to a few thousand requests per second.
The sweet spot on the above chart is clearly the third bar from the left. Optimising your database access is by far the most important thing to get right: after that, removing core pieces of the framework provides diminishing performance returns.
The next step: ETags and network level caching
If performance is a serious concern for your API eventually you'll want to stop focusing on optimizing the Web server and instead focus on getting your HTTP caching right.
The potential for HTTP caching will vary greatly across APIs, depending on the usage patterns and how much of the API is public and can be cached in a shared cache.
In our example above we could place the API behind a shared server-side cache, such as Varnish. If it's acceptable for the user list to exhibit a few seconds lag, then we could set appropriate cache headers to that the cache would only re-validate responses from the server after a small time of expiry.
Getting the HTTP caching right and serving the API behind a shared server-side cache can result in huge performance increases, as the vast majority of your requests are handled by the cache. This depends on the API exhibiting cacheable properties such as being public, and dealing mostly with read requests, but when it is possible the gains can be huge. Caches such as Varnish can happily deal with tens or hundreds of thousands of requests per second.
You can already use Django's default caching behavior with Django REST framework, but the upcoming REST framework 2.4.0 release is intended to include better built-in support.
Scope for improvement
As with any software there is always scope for improvement.
Although the database lookup will be the main performance concern for most REST framework APIs, there is potential for improvement in the speed of serialization. Inside the core of REST framework one other area that could be tweaked for small improvement gains is the content negotiation.
Summary
So, what's the take home?
1. Get your ORM lookups right.
Given that database lookups are the slowest part of the view it's tremendously important that you get your ORM queries right. Use .select_related() and .prefetch_related() on the .queryset attribute of generic views where necessary. If your model instances are large, you might also consider using defer() or only() to partially populate the model instances.
2. Your database lookups will be the bottleneck.
If your API is struggling to cope with the number of requests it's receiving your first code improvement should be to cache model instances appropriately.
You might want to consider using Django Cache Machine or Johnny Cache. Alternatively, write the caching behavior into the view level, so that both the lookup and the serialization are cached.
For example:
class UserListView(APIView):
"""
API View that returns results from the cache when possible.
Note that cache invalidation would also be required.
Invalidation should hook into the model save signal,
or in the model `.save()` method.
"""
def get(self, request):
data = cache.get('users')
if data is None:
users = User.objects.all()
serializer = UserSerializer(users)
data = serializer.data
cache.set('users', data, 86400)
return Response(data)3. Work on performance improvements selectively.
Remember that premature optimization is the root of all evil. Don't start trying to improve the performance of your API until you're in a position to start profiling the usage characteristics that your API clients exhibit. Then work on optimizing your views selectively, targeting the most critical endpoints first.
One of the nice things about REST framework is that because it uses regular Django views, you can easily start to optimize and strip down individual views, while still getting the benefits of working with a proper API framework instead of just using plain Django.
4. You don't always need to use serializers.
For performance critical views you might consider dropping the serializers entirely and simply use .values() in your database queries. If you're using hyperlinked representations or other complex fields you might find you also need to do some post processing on the data structures before returning them in the response. REST framework is designed to make this easy.
Final words
To build high-performance Web APIs, focus on the right things. Use a mature, well supported, well tested and fully featured Web API framework such as REST framework, and work on improving on your API's architecture rather than the details of the framework code. Proper caching of serialized model instances and optimal usage of HTTP caching and server side caches will see huge performance gains when measured against spending time trying to slim down the server framework you're using.